TM1 at scale

I recently had a chance to work on a very large TM1 system and one of my colleagues asked ‘so what can we learn from it?’ This question got me thinking a bit past the usual ‘just don’t do this’ banter and lead to this post.
I think what differs in TM1 implementations when they grow past the 1-2 people projects is that they shift heavier into the traditional software development process from the ’nothing we cannot do with a bit VBA and elbow grease’. At this point, the need for capabilities described below starts outweigh the cost of developing & maintaining them and you start seeing them more prominently.
Take this with a grain of salt, there’s no need to have a ‘separate’ product for each one of these. Rule of the thumb is that if you don’t feel the need – there’s none :) And each one of these is worth a separate post in itself (and as I add links I can see I did some of them already), this is just skimming the surface.
Parallel TI Execution framework
A famous one :)
TM1 doesn’t do parallel process execution out of the box, so you need to roll your own approach with RunTIs or RunProcess.
I’ve described the ideas behind what I usually do in this post, but I saw IBM’s one recently and I’d suggest you look at it before embarking on doing it again, it looks comprehensive and a great place to start, definitely more ‘feature-rich’ than the ones I usually build or see :)
Hopefully, RunProcess will be soon extended to capture the process execution status and will allow us to move on from ‘file semaphores’ approach and make it all a lot more straight-forward.
Code versioning
Another old chestnut.
TM1 has no ‘built-in’ version control paradigm for a while (XRUs anyone?) and it’s something that is definitely lacking. This also explains why I’m so keen on Git integration, I think it can provide all the ‘industry-standard’ code maintenance approaches and utilities to TM1. Millions of people use Git every day and it has a very well developed ecosystem.
In the very basic form, I usually see something like a special folder with old versions of code & comments
What I’d want is versioning built in the code editor. I haven’t seen this properly anywhere so far, maybe it’ll come over time. It’ll be interesting to see whether IBM will extend PaW editors to be ‘versioning-aware’ as I’d much prefer a VSCode plugin. As with a lot of these, I think trying to match a full-blow IDE with a large userbase and plugin ecosystem is a waste of development resources :)
Deployment / promotion mechanism
It’s 2020 and we’re still promoting objects via copy file & restart, I have strong feelings about it.
Some form of tooling around it starts with an Excel spreadsheet that would generate you a ‘promotion’ folder that you carry over with a server restart and scales up to a system that does this extract from source / stop target/copy to target/start target automatically.
I haven’t seen a good & robust ‘hot’ (without restart) promotion tool so far, another reason I have such high hopes for Git integration. But I was very excited for Transfer specifications in Performance Modeler a while ago and we all know how that panned out.
Testing maturity & automation
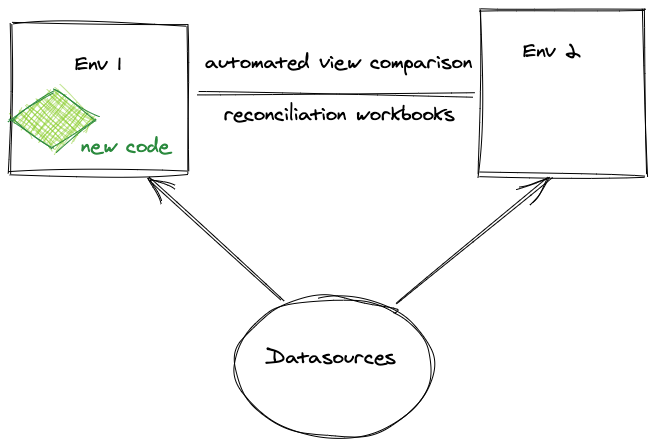
At some point along the way, you need to start separating ’testing’ from ‘development’ in TM1 activities. It can be as simple as a BA running a few reconciliation workbooks and scale up to something that will run automatically and give you a ‘green-light’ that everything is good. Building automated comparisons is a lot simpler these days with REST API as you can automate a lot of defined rules.
In large enough system your ability to estimate the impact of new development is greatly diminished and at this point, I’m a big fan of parallel running 2 systems for testing that allow you to run the same process (es) in 2 identical environments (same data sources, same data in cubes) with the only difference being the new code you’re about to release. This allows you to ensure that all the differences between the environments are the one you ’ expected/trying to address’ and not something new. Dramatically increases my confidence levels and makes promotion less stressful :)
[
Server monitoring and alerts
As your server footprint/user base grows, you start to need to answer ‘why was X slow’ kind of questions that can have a million different reasons. Having something to look at and see CPU / memory/disk utilisation at a time is great. Special bonus if you can see it by TM1 service and all other related processes and multiple servers in the cluster.
And, yeah, you want to know that you are running out of disk for logs or out of memory before the fact, so yay for alerting.
This is an area quite well covered by great tools and your organisation already probably uses a few of them, so I’d say go to infrastructure team with cake and try to figure out how to best set this up.
If your servers are in the cloud, it’s a lot easier as a lot of the basic monitoring and alerting capabilities are built-in.
Load balancing architectures
True high-availability is still impossible for TM1 server itself, but client-facing application servers allow load balancing these days: Tm1web , Planning Analytics Workspace.
Log analysis
I wrote a bit about transaction log analysis at scale here, but even tm1server.log analysis becomes a bit of an effort once you have a few busy boxes.
Questions like ‘how long Update P&L process took last night? Or the day before? What’s the trend over the year? How long does it take in UAT vs Production?’ become harder to answer, especially if you want to correlate it with the server load logs from the point above. Or ‘what is really taking the most time in our parallel overnight process extravaganza?’
Everyone builds a TM1 cube to store TI run time as a starting point, but this solution has a few limitations (retention, need to add ‘start/end’ steps in processes, multi servers, visualisations) that you start hitting after a while.
I hope I get a chance to use something like ELK (or maybe Splunk, but I’d rather use ELK) for this someday, a fast full-text search could be very useful and the ability to be ‘alerted’ on trends (i.e. our overnight load is taking 20% longer than average) can save a fair bit of analysis time. And the nice charts :)
Server configuration management
If things ever get out of control really big and you have multiple servers in multiple environments (say, more than 10 machines), it might be worth having a look at configuration management tools that will allow you to:
- have a single source of all your configuration files (tm1s.cfg, BI, tm1web configs) and make sure they are consistent and selectively update servers
- be able to install product updates automatically
This is what I’ve been busy with over the last 6 months, creating an ability to go ‘I want a new UAT environment’ or ‘I want a new fix pack rolled out to these servers’ without manual intervention. Infrastructure & configurations as code, yay!