TM1 MDX querying snippet

I’m playing around with some TM1 ideas and all of them require some sort of sparsity analysis. And since TM1 supports MDX (to some extent, to say it mildly) and I like MDX and used it a lot with Essbase, I thought it’d be wonderful to use MDX.
And any post is better with a cat picture in it, don’t you agree? This one is about a casual TM1 developer embrasing the ocean of MDX possibilities.
But MDX-dialect of TM1 isn’t well-documented (again, being very polite), so learning it’s intricacies is mostly trial and error and an open field for experiments. And whilst you can write MDX-driven subset definitions (wonderfully described by Phillip Bichard and Martin Findon) in Architect, there’s no actual tool where you can write “select years on rows, measures on columns from sales” and see you table (all the Cognos studios do that, but in background and with quite inefficient way of writing you own). You can go wild on the ODBO page of a TI process as well, but that’s a bit hard from error handling and results viewing.
So at the end of a day I wrote a small Java based script that allows you to write MDX queries to your TM1 server and get result back as a csv file (there’s an Excel workbook doing the same thing, but I’m a Java guy and I needed the querying code to conquer the universe anyway).
How does it work?
- You fill in a query you want to fire in an xml file with some additional options (admin server, login/password, file to write query results to, will you need headers and all that)
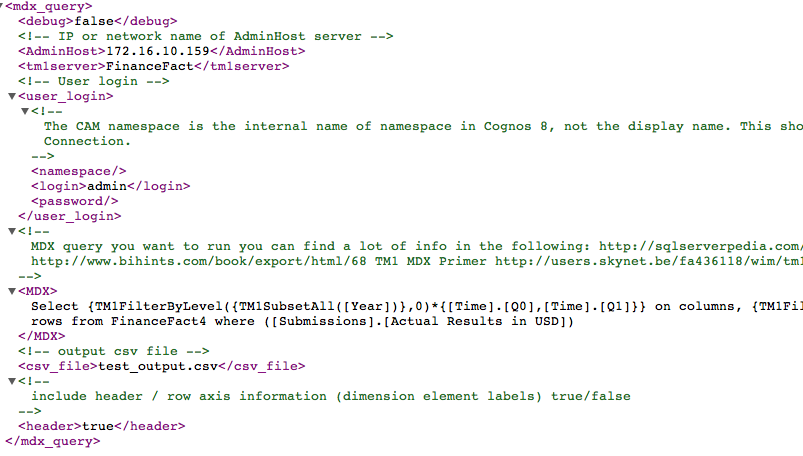
- Run java tm1_mdx your_query_file.xml and get either an incorrect MDX syntax error (bad, I get this often) or results in a CSV file (good)
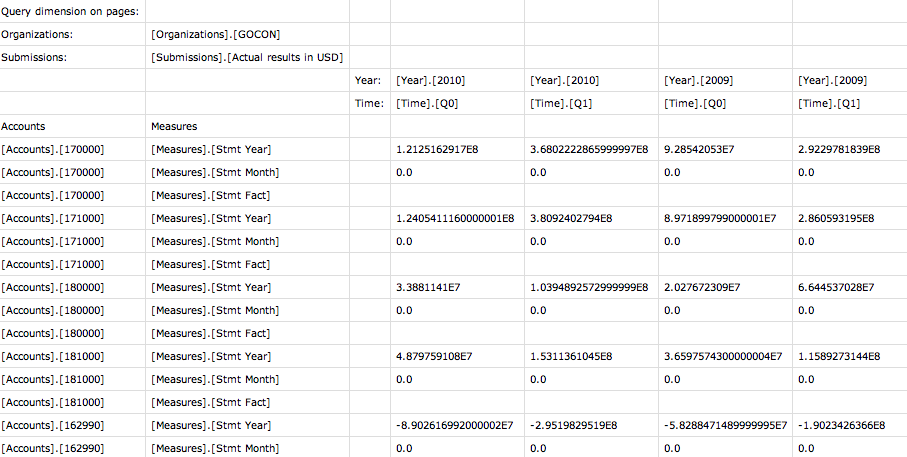
As usual, there’s source code in the package, so you can adjust it \ use it as a base for something bigger.
How to install it?
- You will need Java runtime engine (jre). This the only requirement, there’s no need to have TM1 installed or anything.
- Download the tool (this package is for 9.5.2, ping me if you want it for some newer\older version, it’s just a matter of recompiling), unpack to some directory (c:\tm1mdx, for example)
- Cryptic step of adding security certificate to your Java.
- Find jre\bin\keytool.exe utility on your computer
- Open the command line and navigate to jre\bin
- Run command line keytool -keystore ..\lib\security\cacerts -alias Company -import -file c:\tm1mdx\applixca.der
- Enter ‘changeit’ as password
- Type yes
- Fill in the mdx_query.xml
- Open command line, navigate to c:\tm1mdx, run java tm1_mdx mdx_query.xml
PS: By the way, I glimpsed into TM1 10.1 API docs and all the APIs were greatly enhanced in this version (mostly for Performance Modeler, it seems), so you finally have a per line grained access to rule files and such. It’s obvious that Performance Modeler uses Java API (it’s using Cognos Rich Client Platform, it’s inevitable), so it’s extensively used and developed and might even get documented at some point )
PSPS: It’s interesting whether there’ll be any IBM-made XML/A driver for TM1 at some stage. It seems possible to do a straw olap4j driver for TM1 even now and that’d be a funny way of opening it up a bit further.